

Bing has introduced “Make Every feature Binary” (MEB), a large-scale sparse model that complements its production Transformer models to improve search relevance, the company announced Wednesday. This new technology, which is now running on 100% of Bing searches in all regions and languages, has resulted in a nearly 2% increase in clickthrough rate for the top search results, a reduction in manual query reformulation by more than 1% and a 1.5% reduction of clicks on pagination.
What MEB does. MEB maps single facts to features, which helps it achieve a more nuanced understanding of individual facts. The goal behind MEB seems to be to better mimic how the human mind processes potential answers.
This stands in contrast to many deep neural network (DNN) language models that may overgeneralize when filling in the blank for “______ can fly,” Bing provided as an example. Most DNN language models might fill the blank with the word “birds”.
“MEB avoids this by assigning each fact to a feature, so it can assign weights that distinguish between the ability to fly in, say, a penguin and a puffin,” Bing said in the announcement, “It can do this for each of the characteristics that make a bird—or any entity or object for that matter—singular. Instead of saying ‘birds can fly,’ MEB paired with Transformer models can take this to another level of classification, saying ‘birds can fly, except ostriches, penguins, and these other birds.’”
Discerning hidden intent. “When looking into the top features learned by MEB, we found it can learn hidden intents between query and document,” Bing said.
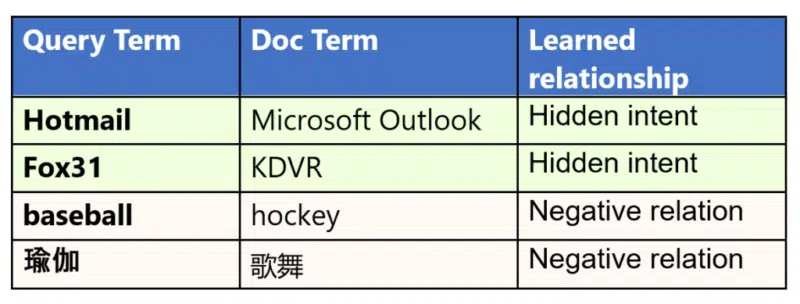
MEB was able to learn that “Hotmail” is strongly correlated to “Microsoft Outlook,” even though the two aren’t close in terms of semantic meaning. Hotmail was rebranded as Microsoft Outlook and MEB was able to pick up on this relationship. Similarly, it learned the connection between “Fox31” and “KDVR” (despite there being no overt semantic connection between the two phrases), where KDVR is the call sign of the TV channel that operates under the brand Fox31.
MEB can also identify negative relationships between phrases, which helps it understand what users don’t want to see for a given query. In the examples Bing provided, users searching for “baseball” don’t typically click on pages talking about “hockey” even though the two are both popular sports, and the same applies to 瑜伽 (yoga) and documents containing 歌舞 (dancing and singing).
Training and scale. MEB is trained on three years of Bing search that contain more than 500 billion query/document pairs. For each search impression, Bing uses heuristics to gauge whether the user was satisfied with the result they clicked on. The “satisfactory” documents are labeled as positive samples and other documents in the same impression are labeled as negative samples. Binary features are then extracted from the query text, document URL, title and body text of each query/document pair and fed into a sparse neural network model. Bing provides more specific details on how MEB works in its official announcement.
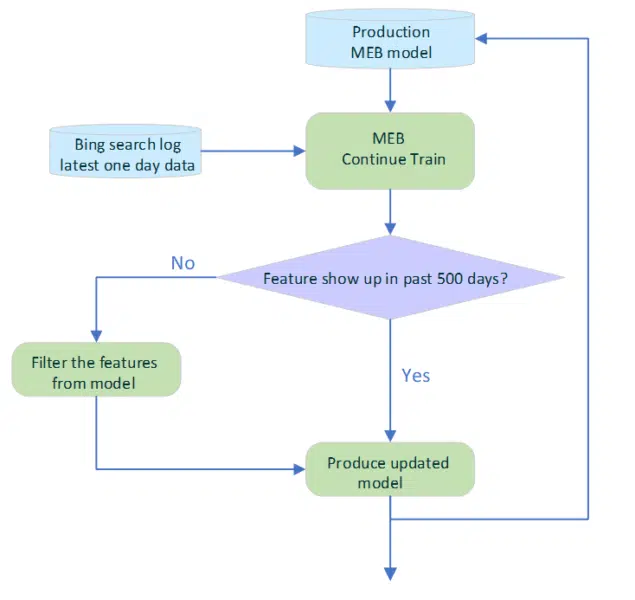
Even after being implemented into Bing, MEB is refreshed daily by continuously training on the latest daily click data (as shown above). To help mitigate the impact of stale features, each feature’s timestamps are checked and the ones that have not shown up in the last 500 days are filtered out. The daily deployment of the updated model is also fully automated.
What it means for Bing Search. As mentioned above, introducing MEB on top of Bing’s production Transformer models has resulted in:
- An almost 2% increase in clickthrough rate on the top search results (above the fold) without the need to scroll down.
- A reduction in manual query reformulation by more than 1%.
- A reduction of clicks on pagination by over 1.5%.
Why we care. Improved search relevance means that users are more likely to find what they’re looking for faster, on the first page of results, without the need to reformulate their queries. For marketers, this also means that if you’re on page 2 of the search results, your content probably isn’t relevant to the search.
MEB’s more nuanced understanding of content may also help to drive more traffic to brands, businesses and publishers, since the search results may be more relevant. And, MEB’s understanding of correlated phrases (e.g., “Hotmail” and “Microsoft Outlook”) and negative relationships (e.g., “baseball” and “hockey”) may enable marketers to spend more time focusing on what customers are really searching for instead of fixating on the right keywords to rank higher.
For the search industry, this may help Bing maintain its position. Google has already laid out its vision for MUM (although we’re far from seeing its full potential in action), and MEB may bolster Bing’s traditional search capabilities, which will help it continue to compete against the industry leader and other search engines.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.


{kind=link}