

An 80 percent decrease in organic traffic is the nightmare of every business. Unfortunately, such a nightmarish scenario may become reality if a website migration is done incorrectly; instead of improving the current situation it eventually leads to catastrophe.

Source: https://take.ms/V6aDv
There are many types of migrations, such as changing, merging or splitting the domains, redesigning the website or moving to a new framework.
Web development trends are clearly showing that the use of JavaScript has been growing in recent years and JavaScript frameworks are becoming more and more popular. In the future, we can expect that more and more websites will be using JavaScript.
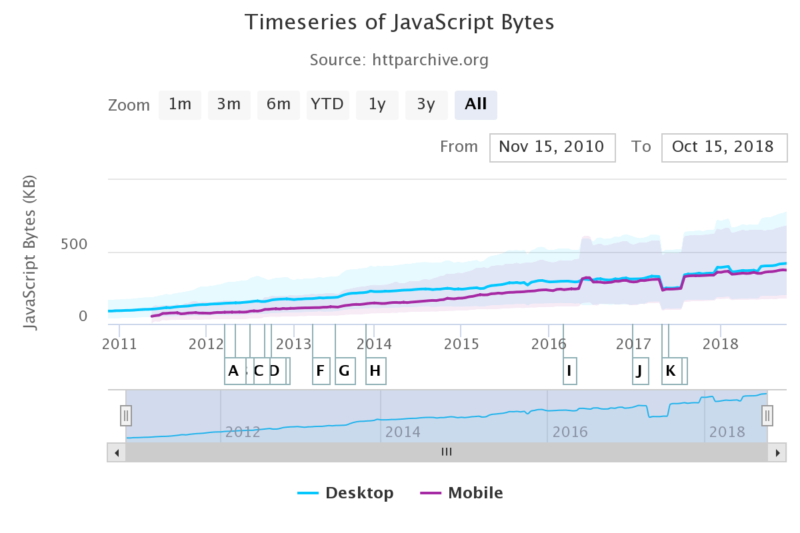
Source: https://httparchive.org/reports/state-of-javascript
As a consequence, SEOs will be faced with the challenge of migrating to JavaScript frameworks.
In this article, I will show you how to prepare for a migration of a website built with a static HTML to a JavaScript framework.
Search engines vs. JavaScript
Google is the only search engine that is able to execute JavaScript and “see” the elements like content and navigation even if they are powered by JavaScript. However, there are two things that you always need to remember when considering changes to a JS framework.
Firstly, Google uses Chrome 41 for rendering pages. This is a three-year old browser that does not support all the modern features needed for rendering advanced features. Even if they can render JS websites in general, it may happen that some important parts will not be discovered due to the reliance on technology that Google can’t process.
Secondly, JS executing is an extremely heavy process so that Google indexes JS websites in two waves. The first wave gets the raw HTML indexed. In the case of JS-powered websites, this translates to almost an empty page. During the second wave, Google executes JavaScript so they can “see” the additional elements loaded by JS. Then they are ready for indexing the full content of the page.

The combination of these two elements makes it so that if you decide to change your current website to the JavaScript framework, you always need to check if Google can efficiently crawl and index your website.
Migration to a JS framework done right
SEOs may not like JavaScript, but it doesn’t mean that its popularity will stop growing. We should get prepared as much as we can and implement the modern framework correctly.
Below you will find information that will help you navigate through the process of changing the current framework. I do not provide “ready-to-go” solutions because your situation will be the result of different factors and there is no universal recipe. However, I want to stress the elements you need to pay particular attention to.
Cover the basics of standard migration
You can’t count on the miracle that Google will understand the change without your help. The whole process of migration should be planned in detail.
I want to keep the focus on JS migration for this article, so if you need detailed migration guidelines, Bastian Grimm has already covered this.
Source: Twitter
Understand your needs in terms of serving the content to Google
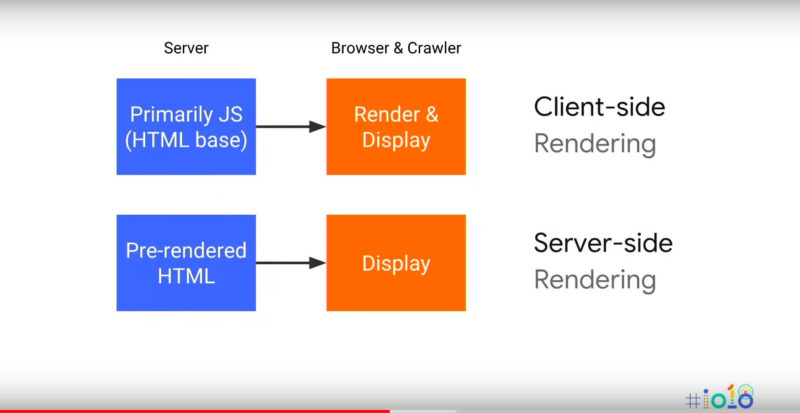
This step should be done before anything else. You need to decide on how Google will receive the content of your website. You have two options:
1. Client-side rendering: This means that you are totally relying on Google for rendering. However, if you go for this option you agree on some inefficiency. The first important drawback of this solution is the deferred indexing of your content due to the two waves of indexing mentioned above. Secondly, it may happen that everything doesn’t work properly because Chrome 41 is not supporting all the modern features. And last, but not least, not all search engines can execute JavaScript, so your JS website will seem empty to Bing, Yahoo, Twitter and Facebook.
Source: YouTube
2. Server-side rendering: This solution relies on rendering by an external mechanism or the additional mechanism/component responsible for the rendering of JS websites, creating a static snapshot and serving it to the search engine crawlers. At the Google I/O conference, Google announced that serving a separate version of your website only to the crawler is fine. This is called Dynamic Rendering, which means that you can detect the crawler’s User Agent and send the server-side rendered version. This option also has its disadvantages: creating and maintaining additional infrastructure, possible delays if a heavy page is rendered on the server or possible issues with caching (Googlebot may receive a not-fresh version of the page).
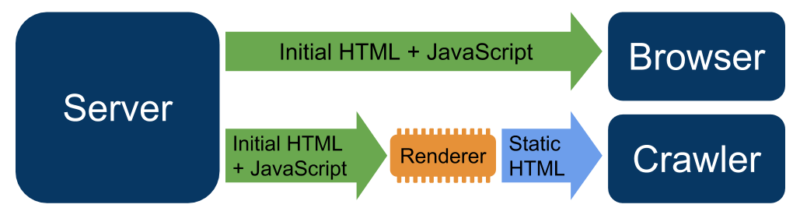
Source: Google
Before migration, you need to answer if you need option A or B.
If the success of your business is built around fresh content (news, real estate offers, coupons), I can’t imagine relying only on the client-side rendered version. It may result in dramatic delays in indexing so your competitors may gain an advantage.
If you have a small website and the content is not updated very often, you can try to leave it as client-side rendered, but you should test before launching the website if Google really does see the content and navigation. The most useful tools to do so are Fetch as Google in GSC and the Chrome 41 browser.
However, Google officially stated that it’s better to use Dynamic Rendering to make sure they will discover frequently changing content correctly and quickly.
Framework vs. solution
If your choice is to use Dynamic Rendering, it’s time to answer how to serve the content to the crawlers. There is no one universal answer. In general, the solution depends on the technology AND developers AND budget AND your needs.
Below you will find a review of the options you have from a few approaches, but the choice is yours:
- I need an as simple a solution as possible.
Probably I’d go for pre-rendering, for example with prerender.io. It’s an external service that crawls your website, renders your pages and creates static snapshots to serve them if a specific User Agent makes a request. A big advantage of this solution is the fact that you don’t need to create your own infrastructure.
You can schedule recrawling and create fresh snapshots of your pages. However, for bigger and frequently changing websites, it might be difficult to make sure that all the pages are refreshed on time and show the same content both to Googlebot and users.
- I need a universal solution and I follow the trends.
If you build the website with one of the popular frameworks like React, Vue, or Angular, you can use one of the methods of Server Side Rendering dedicated to a given framework. Here are some popular matches:
- Angular Universal is a solution for Angular.
- Nuxt.js goes with Vue.js.
- React is supported by Next.js.
Using one of these frameworks installed on the top of React or Vue results in creating a universal application, meaning that the exact same code can be executed both on the server (Server Side rendering) and in the client (Client Side Rendering). It minimizes the issues with a content gap that you could have if you rely on creating snapshots and heavy caching, as with prerender.
- I need a universal solution and I don’t use a popular framework.
It may happen that you are going to use a framework that does not have a ready-to-use solution for building a universal application. In this case, you can go for building your infrastructure for rendering. It means that you can install a headless browser on your server that will render all the subpages of your website and create the snapshots that are served to the search engine crawlers. Google provides a solution for that – Puppeteer is a library that does a similar job as prender.io. However, everything happens on your infrastructure.
- I want a long-lasting solution.
For this, I’d use hybrid rendering. It’s said that this solution provides the best experience both to users and the crawlers because users and crawlers receive a server-side rendered version of the page on the initial request. In many cases, serving an SSR page is faster for users rather than executing all the heavy files in the browser. All subsequent user interactions are served by JavaScript. Crawlers do not interact with the website by clicking or scrolling so it’s always a new request to the server and they always receive an SSR version. Sounds good, but it’s not easy to implement.

Source: YouTube
The option that you choose will depend on many factors like technology, developers and budgets. In some cases, you may have a few options, but in many cases, you may have many restrictions, so picking a solution will be a single-choice process.
Testing the implementation
I can’t imagine a migration without creating a staging environment and testing how everything works. Migration to a JavaScript framework adds complexity and additional traps that you need to watch out for.
There are two scenarios. If for some reason you decided to rely on client-side rendering, you need to install Chrome 41 and check how it renders and works. One of the most important points of an audit is checking errors in the console in Chrome Dev Tools. Remember that even a small error in processing JavaScript may result in issues with rendering.
If you decided to use one of the methods of serving the content to the crawler, you will need to have a staging site with this solution installed. Below, I’ll outline the most important elements that should be checked before going live with the website:
1. Content parity
You should always check if users and crawlers are seeing exactly the same content. To do that, you need to switch the user agents in the browser to see the version sent to the crawlers. You should verify the general discrepancies regarding rendering. However, to see the whole picture you will also need to check the DOM (Document Object Model) of your website. Copy the source code from your browser, then change the User Agent to Googlebot and grab the source code as well. Diffchecker will help you to see the differences between the two files. You should especially look for the differences in the content, navigation and metadata.
An extreme situation is when you send an empty HTML file to Googlebot, just as Disqus does.
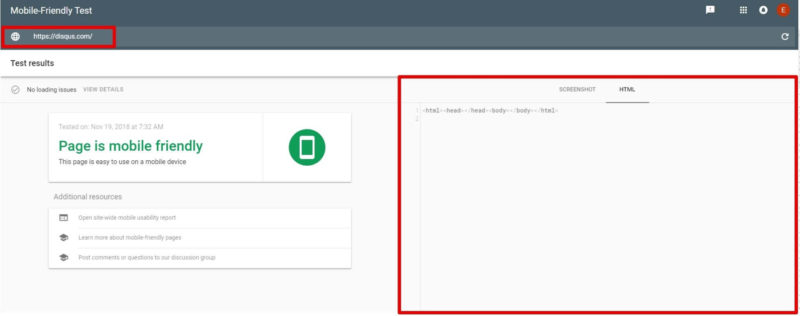
Source: Google
This is what their SEO Visibility looks like:
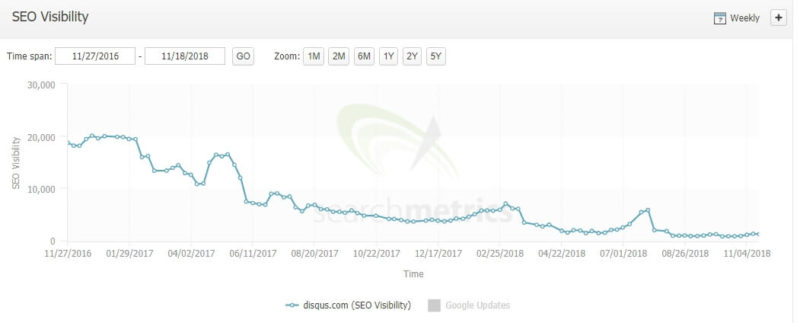
Source: https://take.ms/Fu3bL
They’ve seen better days. Now the homepage is not even indexed.
2. Navigation and hyperlinks
To be 100 percent sure that Google sees, crawls and passes link juice, you should follow the clear recommendation of implementing internal links shared at Google I/O Conference 2018.

Source: YouTube
If you rely on server-side rendering methods, you need to check if the HTML of a prerendered version of a page contains all the links that you expect. In other words, if it has the same navigation as your client-side rendered version. Otherwise, Google will not see the internal linking between pages. Critical areas where you may have problems is facet navigation, pagination, and the main menu.
3. Metadata
Metadata should not be dependent on JS at all. Google says that if you load the canonical tag with JavaScript they probably will not see this in the first wave of indexing and they will not re-check this element in the second wave. As a result, the canonical signals might be ignored.
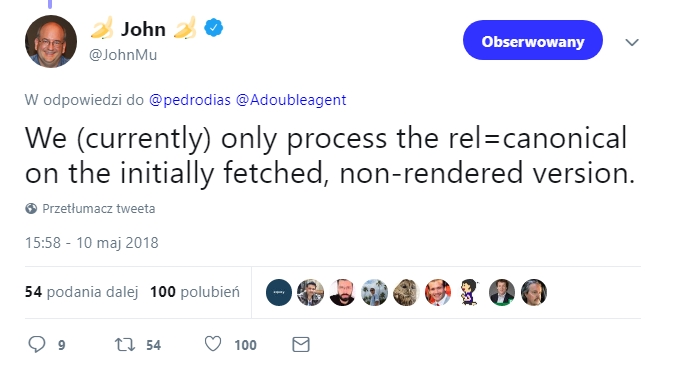
While testing the staging site, always check if an SSR version has the canonical tag in the head section. If yes, confirm that the canonical tag is the correct one. A rule of thumb is always sending consistent signals to the search engine whether you use client or server-side rendering.
While checking the website, always verify if both CSR and SSR versions have the same titles, descriptions and robots instructions.
4. Structured data
Structured data helps the search engine to better understand the content of your website.
Before launching the new website make sure that the SSR version of your website displays all the elements that you want to mark with structured data and if the markups are included in the prerendered version. For example, if you want to add markups to the breadcrumbs navigation. In the first step, check if the breadcrumbs are displayed on the SSR version. In the second step, run the test in Rich Results Tester to see if the markups are valid.
5. Lazy loading
My observations show that modern websites love loading images and content (e.g. products) with lazy loading. The additional elements are loaded on a scroll event. Perhaps it might be a nice feature for users, but Googlebot can’t scroll, so as a consequence these items will not be discovered.
Seeing that so many webmasters are having problems with lazy loading in an SEO-friendly way, Google published a guideline for the best practices of lazy loading. If you want to load images on a scroll, make sure you support paginated loading. This means that if you scroll, the URLs should change (e.g., by adding the pagination identifiers: ?page=2, ?page=3, etc.) and most importantly, the URLs are updated with the proper content, for example by using History API.
Do not forget about adding rel=”prev” and rel=”next” markups in the head section to indicate the sequence of the pages.
Snapshot generation and cache settings
If you decided to create a snapshot for search engine crawlers, you need to monitor a few additional things.
You must check if the snapshot is an exact copy of the client-side rendered version of your website. You can’t load additional content or links that are not visible to a standard user, because it might be assessed as cloaking. If the process of creating snapshots is not efficient e.g. your pages are very heavy and your server is not that fast, it may result in creating broken snapshots. As a result, you will serve e.g. partially rendered pages to the crawler.
There are some situations when the rendering infrastructure must work at high-speeds, such as Black Friday when you want to update the prices very quickly. You should test the rendering in extreme conditions and see how much time it takes to update a given number of pages.
The last thing is caching. Setting the cache properly is something that will help you to maintain efficiency because many pages might be quickly served directly from the memory. However, if you do not plan the caching correctly, Google may receive stale content.
Monitoring
Monitoring post-migration is a natural step. However, in the case of moving to a JS framework, sometimes there is an additional thing to monitor and optimize.
Moving to a JS framework may affect web performance. In many cases, the payload increases which may result in longer loading times, especially for mobile users. A good practice is monitoring how your users perceive the performance of the website and compare the data before and after migration. To do so you can use Chrome User Experience Report.

Source: Google
It will provide information if the Real User Metrics have changed over time. You should always aim at improving them and loading the website as fast as possible.
Summary
Migration is always a risky process and you can’t be sure of the results. The risks might be mitigated if you plan the whole process in detail. In the case of all types of migrations, planning is as important as the execution. If you take part in the migration to the JS framework, you need to deal with additional complexity. You need to make additional decisions and you need to verify additional things. However, as web development trends continue to head in the direction of using JavaScript more and more, you should be prepared that sooner or later you will need to face a JS migration. Good luck!
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.


{kind=link}