

 In the client-server architecture of the World Wide Web, the interaction between browsers and websites is handled through the hypertext transfer protocol (HTTP). This protocol was introduced in 1991 and is an official web standard. Almost all traffic on the web is handled through HTTP.
In the client-server architecture of the World Wide Web, the interaction between browsers and websites is handled through the hypertext transfer protocol (HTTP). This protocol was introduced in 1991 and is an official web standard. Almost all traffic on the web is handled through HTTP.
When search engine spiders like Googlebot crawl a website, they behave like browsers requesting web pages from a site and rely on HTTP for this exchange. This is why it’s important for search engine optimization specialists (SEOs) to understand how the HTTP protocol works and the impact it has on search engines’ crawling and indexing of web pages. In this column, I’ll explain everything you need to know.
But first, let me tell you about the tools you’ll need to perform the necessary tests on your site. Google Chrome DevTools allows you to view a uniform resource locator (URL) full HTTP response, but it can be cumbersome to view. I prefer using the Ayima Page Insights and Ayima Redirect Path Chrome plugins to show me a URL’s full HTTP response.
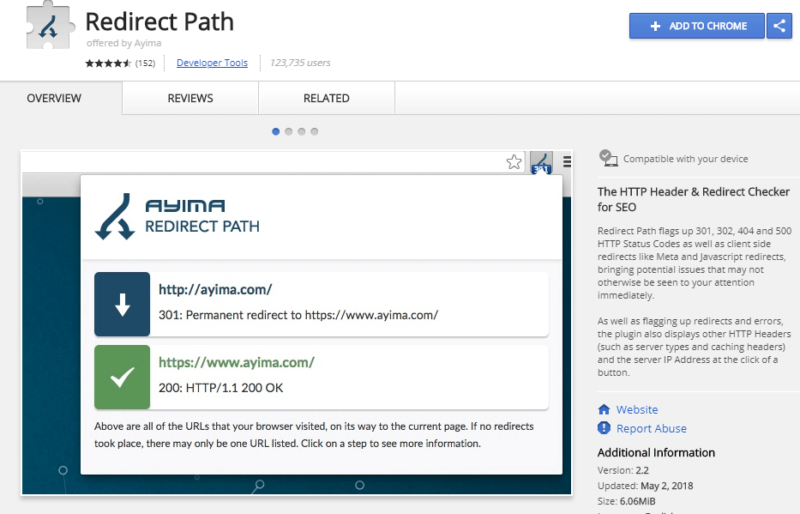

Using the Ayima Page Insights plugin in Chrome, this is what an HTTP response looks like:
Another tool that does the same job is Live HTTP Headers for Chrome.
HTTP status codes
Let’s talk about HTTP status codes.
When a web page is requested from a website, the website’s server responds with an HTTP status code. This code is an acknowledgment of the client’s request and indicates the type of response the server is sending to the client.
There are hundreds of different HTTP status codes that a web server can respond with and you could encounter in your day-to-day search engine optimization (SEO) work. It will help you to familiarize yourself with most of them so you know how to work with them. Here is a list of the more common HTTP status codes:
- 200 OK.
- 300 Multiple choices.
- 301 Moved permanently.
- 302 Moved temporarily.
- 304 Not modified.
- 307 Temporary redirect.
- 400 Bad request.
- 401 Unauthorized.
- 404 Not found.
- 410 Gone.
- 429 Too many requests.
- 500 Internal server error.
- 501 Not implemented.
- 503 Service unavailable.
- 550 Permission denied.
Seach engine optimization specialists need to know these status codes intimately and understand the purpose that each response code serves. Moreover, SEOs should understand how search engines like Google handle these status codes. Let’s look at some of the more common ones.
200 OK
Let’s start with the obvious one. A 200 response from a web server means the request was successful, that the web page that was requested exists and the web server will start sending that page and its associated resources (images, CSS & JS files and so on) to the client.
This response code is very simple. Often, additional headers are sent along with the response code that can impact how search engines handle the URL. We’ll look these in the HTTP Headers section below.
301 moved permanently
The 301 HTTP status code is one of the SEO industry’s favorites because it lets browsers — and search engines — know a web page has been replaced by another page and the change is a permanent one. For search engines, this is a signal they need to update their indexes and associate the old URL’s link metrics with the new URL.
The amount of link value from the original URL that is associated with the new URL through a 301-redirect is a matter of speculation, and Google has given contradictory statements about this.
I believe a 301 redirect has the same PageRank damping factor applied as a link — so when page A redirects to page B, it has the same effect as page A linking to page B.
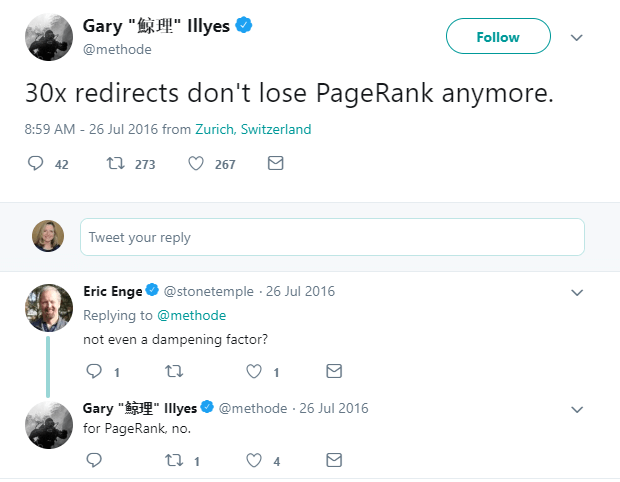
Overall, 301 redirects are a crucial tool in the SEO arsenal and have a wide range of useful applications that can help a website preserve its rankings or even improve them.
302 moved temporarily
The other type of redirect is the 302 HTTP status code, which indicates a page has been temporarily replaced by another URL.
In the short term, this means search engines will keep the original URL in their index, while users are sent to the redirect’s target URL. In the long term, however, Google interprets a 302 redirect as a permanent 301 redirect and will start to handle it accordingly.
Many sites use 302 redirects for automatic geographic redirects, to send users to the correct country/language version of their content. While this may seem fine in theory, it’s generally not recommended to use redirects for this, as it can mean search engines like Google only see one country’s version of the site’s content.
Google crawls primarily from US-based IP addresses, so an automatic 302 redirect for all US traffic means Google would only see a site’s American content. Other country and language versions would be effectively invisible to Google unless you find ways to make exceptions for Googlebot.
304 not modified
The 304 HTTP status code is not used as often as it should. What this code does is inform browsers and search engine crawlers that the resource has not changed since the last visit. This means the resource doesn’t have to be re-sent across the internet, and the client can just rely on the version of the resource that’s been cached.
For large websites, judicious application of 304 status codes can help save a lot of server resources. If you serve 304 resources to Googlebot when a page hasn’t been updated since the last crawl, the page (and all of its associated resources) doesn’t have to be generated or sent across the internet, so you can preserve a lot of central processing unit (CPU) cycles and bandwidth.
307 temporary redirect
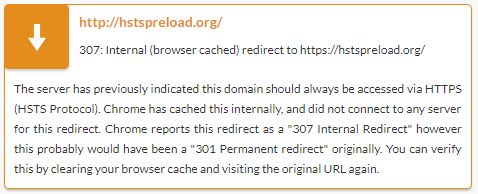
The 307 HTTP status code is a bit of a false flag. We see it from time to time on websites that are served over HTTPS and are on the HSTS preload list. According to the Chromium Projects:
Basically, what happens with a 307 is that the browser recognizes a request made to https://website.com should instead be to a https://website.com and will go straight there.
So it’s not really an HTTP response code; the website’s server never sees the original request. The browser implements this redirect itself, as it knows (due to the HSTS Preload list) that the URL in question is served over HTTPS rather than HTTP. Google, PayPal, Twitter, Stripe, DropBox, Facebook and LastPass are a few of the well-known sites on the preloaded HSTS list.
The Ayima Redirect Path plugin will show this accordingly:
404 not found & 410 gone
In the 400-range of HTTP status codes, there are two I want to highlight since they are important for SEO.
The first and most common one is the 404 not found HTTP status code. This indicates that the URL doesn’t exist, and Google Search Console will show these errors in the site’s Crawl Errors report. Most often, 404 responses are the result of a faulty link somewhere on a website that Google discovers and then tries to crawl.
A website will start serving a 404 not found HTTP response on a page after it has been removed. In my opinion, you shouldn’t allow this to happen. A 404 error is indicative of an accidental error, a wrongly entered link somewhere. If a URL used to serve valid content has since been removed, you shouldn’t serve a 404; you should either 301-redirect the URL to a valid active page or serve a 410 gone status code.
The 410 gone HTTP response is a “deliberate 404.” With the 410 response, you are saying that yes, there used to be a page here, but it’s been permanently removed.
Search engines treat 410s differently than 404s. While both status codes are reported in Google Search Console as “not found” errors, a 410 is a clear signal to Google to remove that URL from its index. While Google will interpret a 404 as an accidental error and will keep a URL serving a 404 in its index for a while, a 410 response is seen as an explicit request to remove that URL from Google’s index.
The following is an older video from ex-Googler Matt Cutts explaining how Google handles 404 and 410 status codes, but it’s still a very good one to watch:
429 too many requests
In the course of your SEO career, you will come across many 4XX HTTP status codes, but few will be as infuriating as the 429 response. You will most likely see this HTTP status code when you’re crawling a website with your favorite SEO crawler tool.
The 429 response indicates a client has made too many requests in a given period, and instead of a URL’s proper response, you get the 429 response instead. This is the result of some form of rate-limiting technology that prevents websites from being overloaded by external requests. Often it will also interfere with crawls on a website by SEO tools, and you may need to ask the website’s tech team to make an exception for the IP address(es) you use for crawling the site.
Some rate-limiting technologies also block Googlebot this way, which could have profound repercussions on the speed and efficiency with which Google can crawl a site.
This can be hard to identify, as Google doesn’t report 429 responses in Search Console. If a website uses rate-limiting technology, it’s always worth double-checking that there is an exception in place for valid Googlebot crawls.
500 internal server error and 503 service unavailable
Any type of 5XX HTTP response indicates some sort of server-side problem. They are codes to avoid as much as possible.
They are quite common, especially on large-scale websites. Google reports these server errors in Search Console:
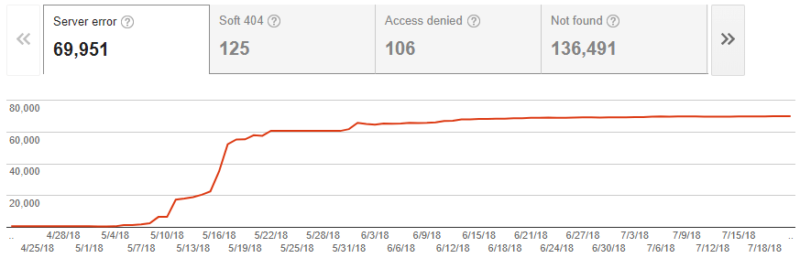
For SEO, the impact of these errors is primarily one of crawl efficiency. Because of the severity of these errors, when a website starts server 5XX-type responses, Googlebot will reduce the rate at which it crawls the site or even stop crawling the site entirely until the errors disappear.
So, these errors have a similar effect as the 429 response and can impact on a site’s crawl rate. The result could be evident in delays in getting new or changed content indexed. As a rule, a website should minimize the number of 5XX HTTP responses it serves.
If you absolutely have to serve a 5XX error message, for example when you’re taking a site down for maintenance, you should always use the 503 service unavailable HTTP status code.
A 503 is to a 500 what a 410 is to a 404: It’s a deliberate signal, so crawlers like Googlebot know you’ve purposefully taken the site down.
When Googlebot sees a 503, it will slow its crawl rate and not change your page’s status in its index. You can safely keep serving 503s while you work on your website with no impact on your site’s rankings in Google.
Only when a 503 error persists for a prolonged period of time will Google start interpreting it as a persistent error and update its index accordingly.
HTTP headers
The status code is just part of the full HTTP response that a server sends to a client. Additional information is sent across with the status code. The full response of a status code plus additional information is called the HTTP header.
This header can contain instructions that clients and search engines can use to properly handle the URL.
Because of the extensible nature of HTTP headers, there is literally no limit to what a URL’s full HTTP header response can contain.
Let’s look at a number of important HTTP header elements for SEO next.
Canonical link
We are used to looking for canonical tags in a web page’s hypertext markup language (HTML) source code. However, you can also send a canonical link as part of a URL’s HTTP Header. This is fully supported by Google and has the exact same impact as a rel=canonical link in the page’s HTML source.
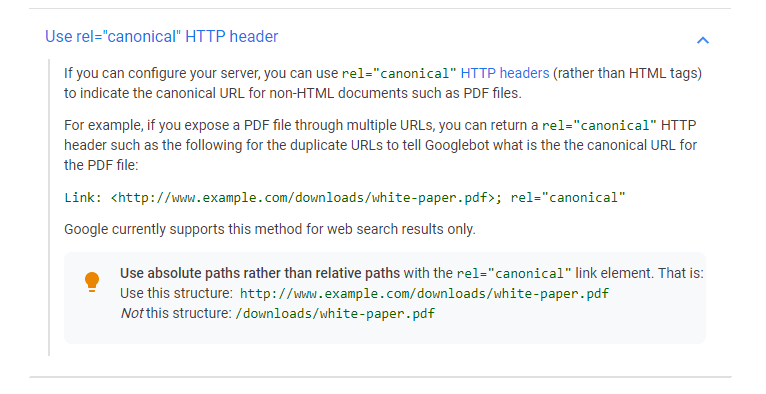
Because it’s relatively easy to implement rel=canonical tags in a page’s HTML, it’s rare to find canonical links sent as part of a page’s HTTP response. However, it’s always worth double-checking the page’s HTTP headers for canonical links, especially if you see unusual indexing and ranking issues on a website.
Hreflang links
In the same way as canonical links, you can also include hreflang links in a page’s HTTP Header response. Hreflang link references indicate that a page has alternate versions targeting different languages and/or countries. Usually, these are included in the page’s HTML source in the header, or as part of an XML sitemap.
Hreflang implementations using HTTP headers are rare, and personally, I’d not recommend it as it can be very tough to troubleshoot. Implementations with extensible markup language (XML) sitemaps are the easiest to manage, followed by HTML link references.
Robots meta tag and X-Robots-Tag
When we want to instruct search engines not to index a page, we can use the robots meta tag to do so. This meta tag tells Googlebot and other search engines not to index a page and also not crawl any links included on the page.

There is a limitation with this meta tag: it can only be implemented on URLs that serve a web page.
For example, you want to make sure all PDF files on your site are not indexed, but you can’t use this meta tag because it doesn’t work with PDF files. Instead, you can use the X-Robots-Tag HTTP header to send the exact same signal.

It’s relatively straightforward to configure a web server to send the X-Robots-Tag HTTP header with the “noindex” value for all files ending in PDF.
On Apache web servers, it is just a few lines of code to add to the site’s .htaccess file:

Because X-Robots-Tag HTTP headers can easily be configured for entire directories, that can also serve as an effective method to prevent search engines from indexing secure folders.
In addition to “noindex” and “nofollow,” you can provide several other X-Robots-Tag responses that affect how Google handles the URL:

Cache-control
Another set of HTTP header responses can influence how a browser caches a page and its associated resources. For example, you can provide a “max-age” response which tells a browser that after a certain amount of time the page needs to be re-requested from the server.

Cache-control headers primarily affect a page’s subjective (re)load speed and won’t have a huge impact on how search engines crawl and index the page. Nonetheless, due to the importance of load speed for SEO and usability in general, it’s worth familiarizing yourself with these HTTP headers to make sure you can provide accurate and valuable advice to a client who wants to enhance a website’s load speed.
Vary
The Vary HTTP header serves a range of purposes relating to compression, cookies and mobile websites.
For use with mobile websites it is especially important, when a site uses dynamic serving for mobile users, to serve a specific Vary HTTP header so that search engines know to crawl the site with both desktop and mobile crawlers. This specific HTTP header is Vary: User-Agent.
This HTTP header tells Googlebot that the site will serve different code to desktop and mobile users. As a result, Google will crawl the site with both types of user-agent and determine which version of the code to rank for which type of users.

HTTP headers for security
While not directly related to SEO, helping a site be more secure is never a bad thing.
HTTP headers play a big role in security, too, as proper use of the right HTTP headers can make a website less vulnerable to a range of potential security issues.
There are dozens of HTTP headers that serve security purposes, such as:
- Strict-Transport-Security.
- X-XSS-Protection.
- X-Content-Type.
- X-Frame-Options.
We’ve just scratched the surface
I have provided a small sampling of HTTP status codes and HTTP headers. If this article has piqued your interest, the web has countless resources for you to learn more about the HTTP protocol and the web’s client-server architecture, such as:
- The Mozilla Developers website.
- Google’s Developers website.
Becoming well-versed in this aspect of the web will help you be a more effective SEO and also serve you well in other areas of digital marketing.
After all, what we do is mostly focused on the web, so a better understanding of the web’s underlying technologies is quite useful indeed.
Contributing authors are invited to create content for Search Engine Land and are chosen for their expertise and contribution to the search community. Our contributors work under the oversight of the editorial staff and contributions are checked for quality and relevance to our readers. The opinions they express are their own.


{kind=link}